各色 DNA 基因解读内容开发白皮书
声明:
各色科技拥有此手册一切解释权,未经书面许可,任何人不得以任何形式进行增删、节选、翻译、改编、出版及仿制。
各色科技拥有本手册内容的专利、专利申请、商标、版权及其它一切知识产权。该权利主张受法律保护,任何人不得侵犯。
1 背景
为了规范、透明地向各色 DNA 用户呈现解读开发过程,以及相关的科学细节,各色 DNA 产品研发团队编制,并会不断修订此手册。
所有用户都可以在官网(www.gesedna.com)上浏览到手册内容,各色的研发团队以及合作的各领域专家、顾问会严格按照手册规范进行解读内容的开发和版本修订。
1.1 原始数据
2018 年 10 月开始,随着全球著名 DNA 测序公司 Illumina 的 ASA 芯片 (Infinium Asian Screening Array ) 各色联合定制版研发完成,各色开始从 GSA 芯片升级为 ASA 各色联合定制版芯片,各色用户成为首批使用 ASA 各色联合定制版芯片获得测序数据和解读的人群。
2018 年 10 月开始,随着全球著名 DNA 测序公司 Illumina 的 ASA 芯片 (Infinium Asian Screening Array ) 各色深度参与了 Illumina ASA 各色联合定制版芯片的位点设计,参与定制 3 万+ 心理和健康相关基因位点,专用于人类复杂行为与基因科学研究。该芯片一次测量 75 万个 DNA 位点数据。经过算法扩展后可获得 500 万左右的 DNA 位点数据。
该芯片专为包括中国人在内的东亚人定制,Illumina 公司和各色针对 ASA 各色联合定制版的多次测试,表明其测序准确率达 99% 以上。采用权威公司研发的芯片,配合实验室严谨规范的操作,有助于帮助用户获得高质量的 DNA 数据。

各色基于芯片测序数据开发相关的解读产品。
2 开发路线图及质量控制
目前各色 DNA 基因检测及解读产品的版本信息为 v1.5.1。本手册涉及的生产规范及生产流程仅针对该版本呈现的数据和文案内容,产品功能、界面呈现、数据库支持和管理等细节不在说明范围之内。
手册内容会随产品的升级迭代进行修订,并随新版本产品一同发布,不会另行通知。
各色提供的检测解读报告从技术上可以拆分为基因数据,现状测评工具和科普内容三个板块,各个板块的生产流程如图 1 所示。

图1 各色 DNA 解读报告内容开发路线图
2.1 立项
开发相关的基因解读和现状评估需要首先进行立项过程。各色的产品研发、内容和运营团队会定期组织会议,从一系列主题中挑选出适合进一步开发的解读内容。
2.1.1 选题来源
在选择开发方向时,主要有以下几种思路:
用户的反馈。用户会通过各种渠道向小助手和运营团队反馈,各色也会定期组织用户的调研和访谈。用户反馈中提及较多的主题和性状,将是我们下一阶段重点的研发方向;
新近的研究成果。结合国际上相关研究的进展,各色会梳理一段时间内取得了突破性进展,或者取得较多关注的研究成果,将其开发成新的解读项目,更新给用户;
已有内容的进一步细化。随着相关领域的研究推进,一些已有的解读项目可以被进一步的拆分,提供给用户更有信息增量的内容,各色也会及时的优化和更新这一部分项目。
2.1.2 可行性评估
根据以上几种思路得到的研发新性状列表,将会在讨论中进行进一步的可行性评估。评估的内容包括:
研究的充分程度。这一性状是否已经被充分的研究。研究使用什么样的数据库,是否包含中国人群的样本。相关研究成果在学术领域受认可的程度,效应量到底有多大。
用户的理解成本和检测价值。这一概念是否能够被清晰的阐述,不同层次的用户是否都能够正确理解其内涵。有多少用户会关心这个主题和方向,大多数用户是否会认可这个检测内容的价值,是否能够为用户提供一定的知识增量或者对生活方式的改进有所帮助。
开发的难度和时间。根据已有的研究提供解读需要用到多少基因位点,这些位点是否与各色的芯片检测位点重合,是否可以开发相关的现状测评,是否有专业背景的团队成员或合作专家进行科学性的审核和把关,具体开发周期大概需要多长。
2.1.3 确定开发项目
通过综合评估和讨论,各色会确定下一阶段的解读开发任务和时间进度,由产品研发团队的具体成员负责管理整个开发流程。
2.2 查找资料
在开发阶段,各色的研发人员会进行系统的文献阅读和资料查找工作,根据权威的科学研究和数据论证,进行检测位点、测试题目的选取以及科学内容的撰写工作。各色团队重点参考的信息来源包括:
2.2.1 生物信息数据库
各色的研究员会从这些地方查找具体的基因位点信息及相关的研究进展程度:
Hapmap
Ensembl Genome Browser
GWAS catalog
Oxford Brain Imaging Genetics (BIG) Server
SNPedia
OMIM
Clinvar
ACMG
Pharmgkb
![]()
2.2.2 权威科学期刊
各色的研究员会从这些地方了解到最前沿的学术研究进展:
Nature 及其子刊
Science 及其子刊
Lacent 及其子刊
JAMA 及其子刊
Cell Press 系列期刊
PNAS 等其他综合类期刊
Anual Reviews 系列期刊
和心理学、人类学、医学、生物学相关的专业类期刊,如 Psychological Science,American Journal of Clinical Nutrition
2.2.3 行业或专业的信息渠道
除了学术期刊外,各色的研究人员还会通过一些专业的协会、网站、组织机构和内部通讯了解到最前沿的观点、讨论和相关资源。
这些可靠的消息源包括,
UK biobank
Social Science Genetic Association Consortium (SSGAC)
Center for Neurogenomics and Cognitive Research (CNCR, Vrije Universiteit Amsterdam)
23andMe Research
Open Science Framework
Association for Psychological Science
中国心理学会
中国遗传学会
2.2.4 学术搜索平台
各色会在这些地方搜索和特定性状有关的科学研究:
Google Scholar
Proquest
Web of Science
Wiley Online Library
SAGE journals
SpringerLink
ResearchGate
bioRxiv
arXiv
PsyArxiv
Thesis Commons
2.3 挑选位点和确定基因算法
从实验室获得每个用户的 DNA 数据后,各色数据工程师会对 DNA 数据进行质控,确定符合标准后,将 DNA 数据上传至各色数据库,用户可以登录网站查看自己的解读结果。
各色提供算法中使用的所有基因位点列表。每一个位点的解读结论,都有相对应的文献可以参考,各色也在网站列出了这些文献,供用户进行探索。
2.3.1 梳理文献和综述
首先需要深入理解目前关于该性状的的基因研究模式。
以抑郁为例,常见的研究模式包括以下几种:
候选基因研究:根据以往研究经验,发现五羟色胺与抑郁有关,研究者进一步假设,与五羟色胺代谢相关的基因与抑郁相关。研究者会选择一些位点进行研究,发现一些结论。
全基因组关联分析研究:候选基因研究不能发现新的基因位点,全基因组关联分析研究是数据驱动研究,在更大的基因数据和表型数据中,寻找效应位点。
基因和环境交互研究:抑郁作为一种情绪,和生活环境和个人经历息息相关,基因和环境的交互研究发现在不同的环境中,与抑郁相关的基因表达程度不同。
2.3.2 综合以上的探索,开始挑选基因位点
挑选基因位点的原则主要包括:
研究对象是不是中国人。如果是中国人或者东亚人的研究质量较好,优先选择。
成熟的,经过多次重复研究验证的候选基因研究。例如 BDNF 基因 rs6265 位点,在研究中多次发现与抑郁显著相关。
例如,
Kim, J. M., Stewart, R., Kim, S. W., Yang, S. J., Shin, I. S., Kim, Y. H., & Yoon, J. S. (2007). Interactions Between Life Stressors and Susceptibility Genes (5-HTTLPR and BDNF) on Depressionin Korean Elders. Biological Psychiatry, 62(5), 423–428.
全基因组关联分析研究,寻找效应最高的几个位点。通过统计中的 p 值或者 OR 值可以选择, OR 值越大,p 值越小,效应越高。
例如抑郁性状解读中的 rs7647854 位点,该位点来自研究:
Power, R. A., Tansey, K. E., Buttenschøn, H. N., Cohen-Woods, S., Bigdeli, T., Hall, L. S., … & Teumer, A. (2017). Genome-wide association for major depression through age at onset stratification: Major Depressive Disorder Working Group of the Psychiatric Genomics Consortium. Biological psychiatry, 81(4), 325-335.
在这项全基因组关联分析中,这是效应值最高的位点。文章中的说明是:
We identified one replicated genome-wide significant locus associated with adult-onset (>27 years) MDD (rs7647854, odds ratio: 1.16, 95% confidence interval: 1.11-1.21, p = 5.2 × 10-11).
选点还要兼顾国内外差异。例如有的效应位点,在中国人群中分布不好,100% 的中国人都是同一类型,那我们也不会选择,这对中国人没有意义。
除此之外,还需要确认这些选点是否在各色目前检测的570万基因位点范围内。如果这一位点各色没有检测,我们也无法纳入到解读位点中。
以及这些位点之间是否存在连锁不平衡效应。如果有的话,需要予以排除。
2.3.3 最后的综合算法
目前主要的算法是计算 Polygenic Risk Scores,即基因效应累加模式。这一模式在很多研究中显示了较高的预测力。各色会根据研究中的效应量,对位点附上不同的权重,从而得到综合预测结果。
这一算法的介绍如下:
Dudbridge, F. (2013). Power and Predictive Accuracy of Polygenic Risk Scores. PLOS Genetics, 9(3).
这一算法在抑郁中的示例如下:
Power, R. A., Tansey, K. E., Buttenschøn, H. N., Cohen-Woods, S., Bigdeli, T., Hall, L. S., … & Teumer, A. (2017). Genome-wide association for major depression through age at onset stratification: Major Depressive Disorder Working Group of the Psychiatric Genomics Consortium. Biological psychiatry, 81(4), 325-335.
2.3.4 划分用户
每个用户都会得到自己在某个特征上的综合得分,各色根据得分,参考这一特征在人群中实际表现的分布,将人群划分为 2 至 5 类,分别给予不同程度标签,提供不同解读。
最终完成一次基因产品的开发。
各色开发产品的第一原则就是准确。
基因研究模式较多,涉及大量位点,各种研究结论的输出的DNA格式也不统一,所以阅读相关文献,找到效应位点,需要对此类研究非常熟悉,以及了解相关的质控方法。
针对一个基因位点的解释,不能只看一篇文献的结论,要看关于这个位点大部分研究的结论是什么,然后做出判断。比如关于抑郁的一个参考位点 rs1360780,按照多数研究,携带T会增加抑郁的风险,TT 型应该属于抑郁风险更高的人群。这个结果是经过多篇研究结论重复得出的,是更准确的结论。
2.4 现状测试开发
各色的现状测试来源有三类,由我们合作的学术团队提供,来自权威的科学文献,或者由各色自己整理编制,根据来源的不同,在工作流程上也会有一些细微的差别。
2.4.1 合作学术团队提供
各色和很多学术研究机构保持着密切的合作关系,他们也会向各色推荐一些经过验证,数据结构良好的问卷和测试。各色会根据测试的内容,编制报告提供给用户,用户的参与也可以进一步的推进该领域的科学研究进展。
例如共情能力的现状测评,这一研究工具由来自北京大学的合作团队推荐,合作团队之前已经使用这一工具在其他群体中进行过大量的科学验证,证明这些题目能够有效的评估一个人的共情能力高低。
各色得到题目后,根据已有的研究成果划定了测试的指标和分数线,编制解读报告。完成这些工作后,就可以直接提供给用户使用。随着数据量的积累,我们也会再根据各色用户的测试结果,重新进行题目的评估和分数线划分,确保测试结果能够准确反映出各色用户的实际分布情况。
2.4.2 各色通过检索文献得到的工具
从无到有开发一个新的现状测试,各色研究员们的常规工作流程是首先查阅文献资料,看看该领域是否已经有得到一致认可或者广泛使用的测评工具。
在英文文献中,这些工具通常会有带有一些固定的名字,Scale(量尺)、Test(测验)、Inventory(量表)、Measure(测量)、Instrument(工具)、Assessment(评估)、Questionnaire(问卷)、Index(指数)等。
各色会根据文献报告的内容,做出综合评估,挑选出合适的测量工具。评估的内容包括编制和修订过程是否规范,测量的结构和内部一致性是否得到数据验证,施测的群体是否有代表性,以及是否有和各色用户群体特征接近的常模数据。
选择合适的测量工具后,通常还需要以下几个步骤:
翻译。很多工具使用英文编制,各色的研究人员会首先将其翻译成中文,再邀请有国外留学经历和相关学科背景的专家将其回译为英文,与原文进行比对,这一步骤是为了确认翻译内容是否准确表达了原文的内容。
内部施测。在正式上线之前,各色会在内部或者邀请一部分资深用户进行小范围体验。这一步是为了验证工具的信度和效度指标与文献报告的一致。同时,我们会根据这些人的得分重新划定分数线。
进一步验证和调整。随着数据的积累,我们会定期的根据用户数据对这些现状评估工具进行细节的修订和分数线的更新,确保测试结果能够准确反映出各色用户的实际分布情况。
2.4.3 各色自己编制的工具
在一些研究较少的领域,可能没有现成的成套的测量工具,这种情况下,各色也会自己编制一些题目和问卷。具体工作流程如下:
出题。各色会成立内部的出题小组,小组成员需要首先通读该领域的科学文献,明确出题目的后,每人提供一定数量的题目。
题目初步筛选。形成题目后,小组成员组织讨论,筛选掉不合适的项目,挑选合适的题目组成问卷。
小范围施测,确定测量结构。首先邀请一部分资深用户进行小范围体验。根据他们的结果进行统计验证和因素分析,进一步筛选题目,并形成几个确定的测量指标。
再次小范围施测,验证测量结构。这一步是为了验证工具的信度和效度指标与初次施测时一致。同时,我们会根据已有的数据划定分数线。
不断验证和调整。随着数据的积累,各色会定期根据用户数据对这些现状评估工具进行细节的修订和分数线的更新,确保测试结果能够准确反映出各色用户的实际分布情况。
测量工具的有效性是贯穿这个开发过程中最核心的目标,各色会通过后台数据不断验证和优化,呈现给用户具有实用性的,有助于自我探索和提升的测量工具。
2.5 文字内容的生成和审校流程
各色解读报告中的科普内容可能由各色的团队成员撰写,也有可能来自与各色合作的科学团队、专家或外脑贡献。一份标准的科学文案需要包括以下几个开发流程:
2.5.1 初稿撰写
初稿是最重要的一个环节,一个优秀的初稿中有 80% 的内容都会体现在最终版的解读报告上。各色对于初稿的的写作要求有两点,科学、有爱。
科学的部分,要求写在解读报告中的每一句话都需要有对应的科学依据,每一个具体的数字都需要有出处。除了撰写内容之外,整理这些参考文献和资料来源也是必须完成的步骤。
有爱的部分,要求文字内容表达出体贴和关怀,不会给用户造成伤害和不适感,用户在阅读完解读报告之后,整体的感受应该是温暖而有力量。
2.5.2 科学性审校
在完成初稿后,所有的相关内容和参考资料都会被提交给另一位作者,进行科学审校。各色对于审校者有很高的要求,必须要经过系统的科学研究训练,有过科普内容的编辑写作经验,同时还要对审校的主题有过深入的研究。
在这个过程中,各色也会邀请合作的科学团队和专家共同参与。
2.5.3 统稿和文字编辑
完成撰写和科学性的把关后,各色的编辑团队会对内容进一步进行统稿加工和文字编辑。这一环节最重要的一点是,不能在文字中出现过多的陌生概念。虽然各色提供的是大量的科学内容,但我们不希望这些内容是深奥难懂的。
过稿的标准是,任何一个受过高中教育的用户,都能够完整的阅读并理解报告内容,并且整个阅读体验是愉快而不是乏味的。
大到整个报告中的对话语气,小到一个标点符号,都需要经过反复的打磨和确认。
2.6 自动化报告生成
各色会在后台根据确定的基因算法和问卷计分方式将用户结果进行分类。不同的分类标签可以直接调用个性化的解读内容,让每一个用户都能够在各色网站上得到和自己结果相关的个性化报告。
2.7 基于用户数据和反馈的迭代优化
随着用户数据的不断积累,各色会在一段时间内,结合用户的基因数据与现状评估数据,对后台算法进行一定的优化和调整,不断迭代升级。
3 产品元素
一份完整的解读报告,在呈现给用户时,一般包括五个板块的内容:性状说明,基因解读,生活经历,现状测试,更好的你。
目前的网站版本仍处于开发阶段,有一些性状只包括性状说明、基因解读和更好的你三部分的内容,缺失的部分各色研发团队会在近期内补充完善。
3.1 性状说明
对于概念科学定义和遗传影响的解释性文字。
你可以把它当作是有关各色解读项目的维基百科。各色提供了上百个解读项目,这里面包含了大量的科学概念和专业术语,在读懂自己的报告之前,你需要首先对这些解读内容的定义有了解。所以我们在产品设计时将性状说明部分放在了所有内容最前面的位置。
3.1.1 科学定义
根据已有的研究和相关理论对解读内容进行科学的界定和说明。科学定义的篇幅在 100-300 字左右。各色选用的定义需要得到相关领域研究者比较一致的认可,或与绝大多数人的理解相符。
定义需要包含参考来源,必要时需要在后面的参考文献(3.2.4)部分注明出处。
3.1.2 遗传率
遗传率指的是群体水平上,一个特征受遗传影响的程度。遗传率是一个取值在 0 到 1 的数字(通常用百分比来指代),数字越高,代表一个特征受到基因 ( 先天 ) 影响越大。
在研究中,人们一般会使用双胞胎或者有一定血缘关系的家族成员之间,在某些特点上的相关性,来计算遗传率。
最常见的作法,是比较同卵双胞胎(同一个受精卵发育而来,即这对双胞胎的 DNA 完全一样)和异卵双胞胎(由两个受精卵发育而来,所以 DNA 上和普通的兄弟姐妹一样,有 50% 相同)在这些特征上的异同,建立统计模型,得到遗传率的大小。
绝大多数复杂特征的遗传率一般在 30%-80% 左右。各色选用的遗传率数据,一般来自大样本或者元分析研究,如果有针对中国人群的双胞胎实验,我们也会优先为用户呈现中国人群体中的数据。
受到目前研究限制,有些特征因为没有进行双胞胎研究,可能暂时还没有遗传率数据。
3.1.3 基因标签与现状标签
基因标签与现状标签是对用户基因检测结果或参与现状测评结果的最直接的描述。
各色会根据提前确定的算法,结合用户基因位点的信息或现状测评的得分,进行一定的分类。分类是后续提供个性化解读内容的依据。
为了帮助用户准确的理解标签的含义,各色还提供了标签的人群分布信息,即在参与人群中,拥有同样标签的人的具体比例。
3.2 基因解读
基因解读是用户关注最多也是各色产品中非常重要的一个组成部分。
各色会根据独特的算法,将用户在某一个特征上的检测结果划分为不同的几个标签。然后根据标签的划分提供个性化的解读内容。
同时这一部分还包括了解读使用的原始位点信息、不同标签在人群中的分布信息。参考文献和详细的科学说明也会集成在页面中供用户随时浏览。
3.2.1 检测位点说明
各色使用 Illumina 定制芯片一次性检测了 75 万基因位点,使用插补算法可以拓展到千万级的位点。针对每一个具体特征,各色的研发团队会结前沿的研究状况,选出与特征相关的位点进行解读。
在检测位点说明部分,各色会详细的呈现哪些位点与这一特征有关,有效应的碱基对是哪个,以及用户自己在这些位点上的检测结果是什么。
3.2.2 个性化解读报告
针对不同基因标签的人群特点,各色团队经过反复打磨,从具体的生活场景出发,提供了个性化的基因解读报告。
解读报告的全部内容均为各色团队原创,其中涉及科学性的部分,经过了相关领域专家的评估,并且能找到研究依据。随着科学研究进展,解读报告的内容可能会不断升级优化,各色对于这一部分的文字内容拥有最终解释权。
3.2.3 标签的人群分布
标签的人群分布是基于各色所有的基因检测用户群体做出的数据描述,一个特征所对应的不同标签的分布百分比相加和为 100%。
一个标签的百分比越高,代表在参与各色检测的人群中拥有这一基因标签的人数越多。其中在人群中少于 20%的标签会被标记为「稀有标签」。
人群分布仅能代表各色群体中的分布状态,由于参与各色检测的人群在某些方面具有一定的相似性,如学习能力更强,开放性更高,因此各色提供的人群分布可能并不代表中国人群的实际分布。
3.2.4 科学说明与参考文献
科学细节部分详细解释了每一个各色选取的位点在生物学上的功能,以及它如何对这一特征产生了影响。
常见问题部分对用户针对基因报告的经常出现的一些问题进行了具体的说明,例如各色如何进行的检测?如何获取DNA原始数据?如何理解检测报告的内容等。帮助用户更准确的认识基因和自己的检测报告。
参考文献按照先后顺序排列,包括了性状特征,遗传率,个性化解读,位点依据等各部分内容中涉及到具体科学研究的部分。
3.3 生活经历
生活经历是各色 v1.50 改版中的新增内容。这一部分是为了向用户传达这样的信息:一个人的发展,先天的遗传和后天的环境同等重要。
我们希望每一位检测用户都认识到基因并非决定性的,除了基因之外,成长经历中的各种事件都有可能影响到你当下的现状表现。
这一板块是解读报告中信息量最为密集的部分,为了科学准确地传递这些信息,各色首先会通过各种学术期刊数据库,检索出包含性状名等关键词的公开文献,梳理研究学界对这一性状影响因素的普遍共识。
3.3.1 生活事件
生活事件就是指你在日常生活中可能经历的那些事情,在解读报告中列出的都是我们认为有可能会影响到你特定特征表现的重要事件。
各色列出的生活事件并没有穷尽所有可能,也不代表你一定会经历。而是说,经过大量研究反复验证,这些事情有可能会对人群中的一部分人产生影响。如果你经历过其中的一些事件,有可能会增强或者减弱你在某一个特征上的表现水平。
关于「A 影响 B」的研究,一些文献的结论可能是冲突的,各色采信的主要是最近几年内发表在高影响学术期刊上的元分析和综述类文献。
没有元分析支持的内容,各色则考虑期刊的影响因子和文献的引用量,采信那些通过严格控制变量设计的严谨的实验室实验,以及大样本大时间跨度的纵向队列研究。
相同水平的研究中,各色会优先采纳使用中国人群体进行的研究。
根据最终筛选出来的文献,确定每个特定事件对一般人群的影响。
3.3.2 年龄阶段
按照人一生中成长的时间序列,我们将这些可能的影响事件进行了排序。
在不同的人生阶段,产生重要影响的人生事件是不同的,当你还是孩子时,父母的观念、成长的环境、同伴的关注会对你有更大的影响。而当你长大成人之后,个人的选择,生活中突然的变故,产生影响的比例会有所增加。
确定一个生活事件产生作用的具体年龄阶段有几个依据:
某些因素只在关键的年龄阶段有特定影响,比如青春期的同伴和小团体,会在你社会化的过程中会起到独特的作用,而你长大成人之后再结交的新朋友可能就不会参与到这一过程。
某些因素的影响可能是连续的贯穿了很多年龄阶段,这时我们通常会选择发生最频繁的年龄段,比如你在人生的任何阶段都可以谈恋爱,但各色会将这一影响放在 18-25 岁的年龄段内,因为统计数据表明,这是大多数人开始尝试恋爱的阶段。
还有一些影响发生的时间更加有弹性,比如一些突然的变故,自然灾害,亲人离世。这种情况下我们主要依据参考研究所选择的样本群体的年龄阶段。如果参考研究证明地震对儿童的心理健康有影响,各色就会将这一影响因素放在儿童期,以确保正确的转述了科学文献中的内容。
3.3.3 影响程度
对筛选出来的文献,各色根据统计学的公认标准,将效应大小分为从小到大的五个等级。等级越高,代表某一事件对某一性状的影响越大。
事件对某一特征的影响存在方向性,在各色的解读报告中,+ 代表该事件会增强特征表现,- 代表会减弱特征表现。
具体统计量及对应影响等级如下:
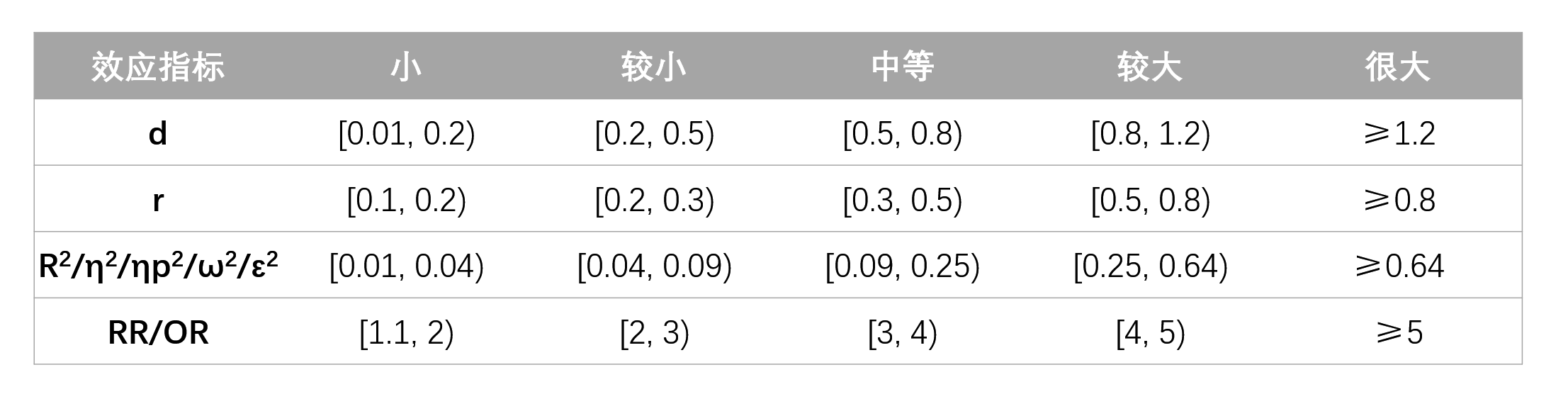
对于缺少效应量或是用到其他效应量的文献,则经过公式转换为上述效应量。
比如,研究发现,父母对孩子的入睡时间有一定的监督作用。相比于父母设定了睡觉时间的孩子,父母未设定睡觉时间的孩子入睡更晚,独立样本 t 检验的结果为 t(519) = 6.825。经公式 d = t*(n1+n2)/sqrt(df*n1*n2) 转换得到 d=0.6,属于中等程度的影响,即,父母监控对晚睡的影响为「—」。
有关效应量部分的具体科学依据,参照下列经典文献:
郑昊敏, 温忠麟, 吴艳. (2011). 心理学常用效应量的选用与分析. 心理科学进展, 19(12), 1868-1878.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Erlbaum.
Ferguson, C. J. . (2009). An effect size primer: a guide for clinicians and researchers. Professional Psychology Research & Practice,40(5), 532-538.
Sawilowsky, S. S. (2009). New effect size rules of thumb. Journal of Modern Applied Statistical Methods, 8(2), 597-599.
3.3.4 科学说明与参考文献
科学说明部分,各色列出了一些用户关注的问题,并给出了答复,随着用户反馈我们也会不断补充完善这一部分的内容,让所有用户都能正确的理解这一部分的信息内容。
参考文献按照先后顺序排列,每一个具体的事件影响都会有对应的研究依据。
3.4 现状测试
各色除了提供 DNA 数据的解读之外,还给用户提供评估自己现状的测试工具。
一个人的表现,由基因、环境和基因环境交互共同影响,DNA 数据解读只能提供先天的倾向,可能与现状不一致。为了帮助用户更全面认识自己,各色提供全面的现状评估工具。
目前,各色为用户提供超过 125 套专业的现状评估工具,这些工具取材于权威学术期刊的主流研究成果,经过反复的验证,具备良好的信度和效度,可以准确的反映你当下的现状表现。

现状测试是为了帮助用户准确理解自己当下的状态,它可能受到当时周围环境和心情影响,在一定时间内也有可能发生变化。
我们会在用户完成的现状测试中标明参与测试的时间,如果你觉得当时的状态不准确,可以选择重新进行测试。
各色鼓励用户在阅读完基因检测报告后,填写一下后面的现状测试内容。通过基因和现状的对比,你可能会对自己产生更深刻的认识。
如果你的先天和后天差别很大,可以对照着生活经历的列表,想一想在自己成长过程中,有哪些重要的事情影响到了你。
有一些特征暂时还不提供现状测试,因为这些特征可能需要在现场或者依靠一些仪器设备测量更加准确。
3.4.1 测试说明
测试的说明部分会介绍测试的出处,版本信息和修订的依据。还有一些必要的信息,题目数量,完成所需的时间和报告的丰富程度,这可以在一定程度上帮助你选择合适的时间或者场景来完成测试。
3.4.2 个性化解读报告
根据用户的测试得分,各色会将参与现状测试的用户分为不同的标签类型。各色团队经过反复打磨,从具体的生活场景出发,为不同分数区间的用户提供了个性化的现状解读报告。
解读报告的全部内容均为各色团队原创,其中涉及科学性的部分,经过了相关领域专家的评估,并且能找到研究依据。随着科学研究进展,解读报告的内容可能会不断升级优化,各色对于这一部分的文字内容拥有最终解释权。
3.4.3 你的得分与具体含义
在解读报告中,各色还会呈现在测量这一特征时所选取的测量指标,有关这些指标的科学说明,以及你在这些指标上的得分。通过对比你的得分,和各色用户总体的分数分布,就可以准确的了解你所处的人群位置。
3.4.4 科学说明与参考文献
科学说明部分,各色列出了一些用户关注的问题,并给出了答复,随着用户反馈我们也会不断补充完善这一部分的内容,让所有用户都能正确的理解这一部分的信息内容。
参考文献主要注明了测量工具的出处,为对测量工具感兴趣的用户提供必要的索引和阅读资料。
3.5 更好的你
对于那些渴望改变的用户,各色提供了一些可以尝试的解决方案。来自群体的研究证明在当下做出一些选择或者采取一些简单的行动就能够帮助一些人变得更好。
这些解决方案主要来自前沿的研究结果,各色会挑选出其中稳定、可靠、被证实有效的内容。
除此之外,我们还会邀请各个领域的专家,比如营养顾问、心理咨询师、健身教练,补充一些专业的行动建议。随着科学研究的进展,各色也会不断迭代升级这一板块的内容。提供更多具有可行性的解决方案。
3.5.1 行动建议
各色提供的行动建议来自基于一般人群的研究结果,或者各色认可的专家分享的经验,但可能并不是每一条建议都完全适合你。在尝试与展开行动的过程中,你将成为自己生活的掌控者,各色团队随时聆听你的反馈。
涉及疾病和医疗部分的内容,各色建议你首先咨询自己的私人医生或专业的医疗机构。各色的内容仅作为你自我探索的参考,不提供医疗相关的诊断和干预。
3.5.2 影响程度
对筛选出来的文献,各色根据统计学的公认标准,将效应大小分为从小到大的五个等级。等级越高,代表采取该行动对某一性状的影响越大。
行动对某一特征的影响存在方向性,各色认为,每个人对于改变的需求是不一样的,但这些改变都是勇气的体现。所以在内容中我们做了区分,你可以根据自己的需要选择合理的内容进行实践。
在各色的解读报告中,+ 代表采取行动会增强特征表现,- 代表会减弱特征表现。
3.5.3 科学说明与参考文献
科学说明部分,各色列出了一些用户关注的问题,并给出了答复,随着用户反馈我们也会不断补充完善这一部分的内容,让所有用户都能正确的理解这一部分的信息内容。
参考文献按照先后顺序排列,有研究依据的行动建议会在参考文献部分列出出处。
4 算法细节
4.1 基因标签如何得到?
各色的绝大多数解读都是通过多基因位点综合评估得到的基因标签。
大部分特征的先天倾向都由多基因、多位点决定。使用位点越多,结果越准确。各色依据国际公开发表的权威文献,选择最具代表性的多个位点,进行个人结论推断,可能未穷尽所有对该特征产生影响的基因变异。
各色检测服务选择的每个检测点都有相关文献支持,并且会不断追踪该领域的最前沿研究结果去更新和提升服务。
拿到测序结果后,各色专业人员首先会根据已有研究确定效应位点( 比如哪种基因型会引起喝酒脸红 ),然后根据各色算法,得出你的综合基因分数,根据基因分数的不同,给出对应的标签( 比如面不改色 ),然后用文字详细描述这一标签可能的具体表现。
个别简单性状受单个基因的调控,各色会选择经过反复研究验证的位点,根据用户在这一位点上不同的基因型给出标签,然后用文字详细描述这一标签可能的具体表现。
还有部分标签评估的并非可能的性状表现,而是根据基因-环境交互模型得到的这一个体在特定环境中的可能的表现。在各色的解读项目中,环境敏感性这一性状符合基因-环境交互作用的模型。
4.2 现状测试的有效性评估
4.2.1 信度评估
信度是指测试结果的一致性、稳定性及可靠性,可以反映随机误差的大小。研究中一般用内部一致性 α 来加以表示该测验信度的高低。
一般科学研究中,会将 α = 0.7 作为测量工具表现良好的标准,各色会用网站数据验证选取的量表的内部一致性,并定期更换掉那些表现不够好的工具。目前在各色的网站上,问卷平均的内部一致性系数达到 0.8。
除了内部一致性系数外,针对重复完成率较高的问卷,各色也会抽样检查一个人在不同时间点多次完成同一个问卷,前后得分的相关性,对于一些较为稳定的个人特点,重测信度一般能达到 0.75 左右。
4.2.2 结构效度检验
结构效度是评价多维度的测试工具有效性的方法。因为很多工具为国外研究者编制,应用在中国人群中,题目之间的结构可能会发生变化。各色会定期对网站上的问卷进行分析,验证测试的结构是否与文献中一致,并根据结果优化计分方式和报告中的文字描述。
4.2.3 效标关联效度
平均每一个参与现状测评的各色用户,在网站上完成了超过 30 份问卷。这些问卷题目彼此之间可能存在着关联,或者相互预测的关系。各色也会定期检验一些相近的测试在得分之间的相关性。例如,情绪稳定性较低的人,焦虑的倾向可能会更高。通过这种相关性可以验证测量的结果是否准确。
5 用户反馈与内容迭代
根据用户的反馈,各色会不断的优化研发工作规范,迭代用户解读报告的内容。
各色目前已经成立了伦理委员会,对各色所有的科研相关项目进行伦理监督,最大保障各色用户的权益。目前伦理委员会成员包括作家阿城,中科院心理所研究员张建新,首都师范大学心理系教授罗劲,知识产权领域资深律师张汣利。伦理委员会是由社会权威人士组成的第三方监督小组。各色伦理委员会无商业利益相关,即伦理委员会成员之间无利益关系,各色与伦理委员会成员无利益关系。
我们使用各种安全技术和程序,以防信息的丢失、不当使用、未经授权阅览或披露。

如果你对白皮书有任何想法或者建议,欢迎通过服务号「各色DNA」(ID:geseloveyou)回复「客服」联系各色团队,或发送邮件至service@gesedna.com。
各色团队会认真聆听每一位用户的宝贵建议。
